go协程原理
| 阅读 | 共 6280 字,阅读约
Overview
协程原理
并发编程模型
- 从内存的角度看,并行计算只有两种:共享内存、消息通讯。
- 目的是解决多线程的数据一致性
CSP模型
- go语言的并发特性是由1978年发布的CSP理论演化而来,另外一个知名的CSP实现语言是Eralng,大名鼎鼎的Rabbitmq就是用erlang实现的。
- CSP是Communicating Sequential Processes(顺序通信进程)的缩写
- CSP模型用于描述两个独立的并发实体通过共享的通讯 channel(管道)进行通信的并发模型。
go对CSP模型的实现
- go底层使用goroutine做为并发实体,goroutine非常轻量级可以创建几十万个实体。
- 实体间通过 channel 继续匿名消息传递使之解耦,在语言层面实现了自动调度,这样屏蔽了很多内部细节
- 对外提供简单的语法关键字,大大简化了并发编程的思维转换和管理线程的复杂性。
- 通过GMP调度模型实现语言层面的调度
理解调度
- 操作系统不认识goroutine,只认识线程
- 调度是由golang的runtime实现的
- 最开始只有GM模型,Groutine都在全局队列,因为性能问题引入了P的概念,将G放入P本地
- 操作系统为什么调度:一个cpu只有一组寄存器,不同线程要用这组寄存器,只能换着使用。本质是寄存器、栈帧的保存和恢复
- Go调度的理解:寻找合适的
调度发展历程
1.14之前:不支持抢占式,存在调度缺陷问题
源码位置:src/runtime/proc.go
1// 获取sudog
2func acquireSudog() *sudog {
3 // Delicate dance: the semaphore implementation calls
4 // acquireSudog, acquireSudog calls new(sudog),
5 // new calls malloc, malloc can call the garbage collector,
6 // and the garbage collector calls the semaphore implementation
7 // in stopTheWorld.
8 // Break the cycle by doing acquirem/releasem around new(sudog).
9 // The acquirem/releasem increments m.locks during new(sudog),
10 // which keeps the garbage collector from being invoked.
11 // 获取当前G对应的M
12 mp := acquirem()
13 // 获取M对应的P
14 pp := mp.p.ptr()
15 // 如果P本地的G列表为空
16 if len(pp.sudogcache) == 0 {
17 // 尝试从调度器的全局队列获取G,所以需要上锁
18 lock(&sched.sudoglock)
19 // First, try to grab a batch from central cache.
20 for len(pp.sudogcache) < cap(pp.sudogcache)/2 && sched.sudogcache != nil {
21 s := sched.sudogcache
22 sched.sudogcache = s.next
23 s.next = nil
24 pp.sudogcache = append(pp.sudogcache, s)
25 }
26 unlock(&sched.sudoglock)
27 // If the central cache is empty, allocate a new one.
28 // 如果调度器也获取不到G,生成一个新的G,并放到本地G列表中
29 if len(pp.sudogcache) == 0 {
30 pp.sudogcache = append(pp.sudogcache, new(sudog))
31 }
32 }
33 n := len(pp.sudogcache)
34 s := pp.sudogcache[n-1]
35 pp.sudogcache[n-1] = nil
36 pp.sudogcache = pp.sudogcache[:n-1]
37 if s.elem != nil {
38 throw("acquireSudog: found s.elem != nil in cache")
39 }
40 releasem(mp)
41 return s
42}
43
44// 释放sudog
45func releaseSudog(s *sudog) {
46 if s.elem != nil {
47 throw("runtime: sudog with non-nil elem")
48 }
49 if s.isSelect {
50 throw("runtime: sudog with non-false isSelect")
51 }
52 if s.next != nil {
53 throw("runtime: sudog with non-nil next")
54 }
55 if s.prev != nil {
56 throw("runtime: sudog with non-nil prev")
57 }
58 if s.waitlink != nil {
59 throw("runtime: sudog with non-nil waitlink")
60 }
61 if s.c != nil {
62 throw("runtime: sudog with non-nil c")
63 }
64 gp := getg()
65 if gp.param != nil {
66 throw("runtime: releaseSudog with non-nil gp.param")
67 }
68 mp := acquirem() // avoid rescheduling to another P
69 pp := mp.p.ptr()
70 // 如果本地G列表已满
71 if len(pp.sudogcache) == cap(pp.sudogcache) {
72 // Transfer half of local cache to the central cache.
73 var first, last *sudog
74 // 将本地G列表的一半数据放到全局队列
75 for len(pp.sudogcache) > cap(pp.sudogcache)/2 {
76 n := len(pp.sudogcache)
77 p := pp.sudogcache[n-1]
78 pp.sudogcache[n-1] = nil
79 pp.sudogcache = pp.sudogcache[:n-1]
80 if first == nil {
81 first = p
82 } else {
83 last.next = p
84 }
85 last = p
86 }
87 lock(&sched.sudoglock)
88 last.next = sched.sudogcache
89 sched.sudogcache = first
90 unlock(&sched.sudoglock)
91 }
92 // 将需要释放被调度的G放到P本地队列
93 pp.sudogcache = append(pp.sudogcache, s)
94 releasem(mp)
95}
并发调度原理
go语言的线程MPG调度模型
M:machine,一个M直接关联一个内核线程 P:processor,代表M所需的上下文环境,也是处理用户级代码逻辑的处理器 G:groutine,协程,本质上是一种轻量级的线程
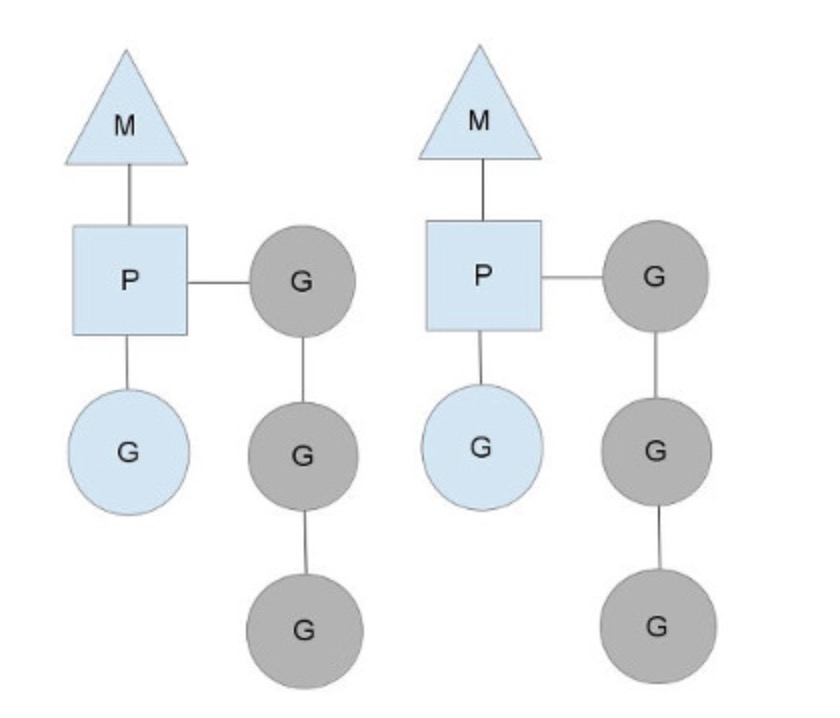
- 一个M对应一个内核线程,也会连接一个上下文P
- 一个上下文P,相当于一个处理器。
- p的数量是在启动时被设置为环境变量
GOMAXPROCS,意味着运行的线程数量是固定的 - 一个上下文连接一个或多个groutine
- p正在执行的Groutine为蓝色的,处于待执行的Groutine为灰色(保存在一个队列中)
G 数据结构
- G对应Groutine
1// 源码位置:src/runtime/runtime2.go
2type g struct {
3 // 栈变量,保存运行时的堆栈内存信息
4 // 内部包含两个指针:lo和hi,分别指向栈的上下界
5 stack stack // offset known to runtime/cgo
6 // 下面两个变量
7 stackguard0 uintptr // offset known to liblink
8 stackguard1 uintptr // offset known to liblink
9 ...
10 // 当前的M,即在哪个线程上执行任务
11 m *m // current m; offset known to arm liblink
12
13 // 存放g的上下文信息(寄存器信息),g被停止调度时,会将上下文信息放到这里,唤醒后可以继续调度
14 // 非常重要的数据信息,替换内核的上下文切换
15 sched gobuf
16 syscallsp uintptr // if status==Gsyscall, syscallsp = sched.sp to use during gc
17 syscallpc uintptr // if status==Gsyscall, syscallpc = sched.pc to use during gc
18 stktopsp uintptr // expected sp at top of stack, to check in traceback
19 // 用于参数传递
20 param unsafe.Pointer // passed parameter on wakeup
21 atomicstatus uint32
22 stackLock uint32 // sigprof/scang lock; TODO: fold in to atomicstatus
23 // g的id
24 goid int64
25 schedlink guintptr
26 // 被阻塞的时间
27 waitsince int64 // approx time when the g become blocked
28 waitreason waitReason // if status==Gwaiting
29
30 preempt bool // preemption signal, duplicates stackguard0 = stackpreempt
31 preemptStop bool // transition to _Gpreempted on preemption; otherwise, just deschedule
32 preemptShrink bool // shrink stack at synchronous safe point
33
34 // asyncSafePoint is set if g is stopped at an asynchronous
35 // safe point. This means there are frames on the stack
36 // without precise pointer information.
37 asyncSafePoint bool
38
39 paniconfault bool // panic (instead of crash) on unexpected fault address
40 gcscandone bool // g has scanned stack; protected by _Gscan bit in status
41 throwsplit bool // must not split stack
42 // activeStackChans indicates that there are unlocked channels
43 // pointing into this goroutine's stack. If true, stack
44 // copying needs to acquire channel locks to protect these
45 // areas of the stack.
46 activeStackChans bool
47
48 raceignore int8 // ignore race detection events
49 sysblocktraced bool // StartTrace has emitted EvGoInSyscall about this goroutine
50 sysexitticks int64 // cputicks when syscall has returned (for tracing)
51 traceseq uint64 // trace event sequencer
52 tracelastp puintptr // last P emitted an event for this goroutine
53
54 // 被锁定只在这个M上执行
55 lockedm muintptr
56 sig uint32
57 writebuf []byte
58 sigcode0 uintptr
59 sigcode1 uintptr
60 sigpc uintptr
61 // 创建groutine的入口指令
62 gopc uintptr // pc of go statement that created this goroutine
63 ancestors *[]ancestorInfo // ancestor information goroutine(s) that created this goroutine (only used if debug.tracebackancestors)
64 // 被执行函数
65 startpc uintptr // pc of goroutine function
66 racectx uintptr
67 waiting *sudog // sudog structures this g is waiting on (that have a valid elem ptr); in lock order
68 cgoCtxt []uintptr // cgo traceback context
69 labels unsafe.Pointer // profiler labels
70 // 缓存的定时器
71 timer *timer // cached timer for time.Sleep
72 selectDone uint32 // are we participating in a select and did someone win the race?
73
74 // Per-G GC state
75
76 // gcAssistBytes is this G's GC assist credit in terms of
77 // bytes allocated. If this is positive, then the G has credit
78 // to allocate gcAssistBytes bytes without assisting. If this
79 // is negative, then the G must correct this by performing
80 // scan work. We track this in bytes to make it fast to update
81 // and check for debt in the malloc hot path. The assist ratio
82 // determines how this corresponds to scan work debt.
83 gcAssistBytes int64
84}
85
86// 保存栈内存地址的数据结构
87type stack struct {
88 // 栈顶,低地址
89 lo uintptr
90 // 栈底,高地址
91 hi uintptr
92}
93
94// 保存上下文寄存器信息的数据结构
95// 核心就是保存寄存器信息
96type gobuf struct {
97 // The offsets of sp, pc, and g are known to (hard-coded in) libmach.
98 //
99 // ctxt is unusual with respect to GC: it may be a
100 // heap-allocated funcval, so GC needs to track it, but it
101 // needs to be set and cleared from assembly, where it's
102 // difficult to have write barriers. However, ctxt is really a
103 // saved, live register, and we only ever exchange it between
104 // the real register and the gobuf. Hence, we treat it as a
105 // root during stack scanning, which means assembly that saves
106 // and restores it doesn't need write barriers. It's still
107 // typed as a pointer so that any other writes from Go get
108 // write barriers.
109 // 执行sp寄存器
110 sp uintptr
111 // 执行pc寄存器
112 pc uintptr
113 // 指向G本身
114 g guintptr
115 ctxt unsafe.Pointer
116 ret sys.Uintreg
117 lr uintptr
118 bp uintptr // for GOEXPERIMENT=framepointer
119}
P 数据结构
- P是一个抽象的概念,并不是真正的物理cpu
- 当p有任务时,需要创建或唤醒一个系统线程来执行它队列里的任务,所以P和M需要进行绑定,构成一个可执行单元
- 可通过GOMAXPROCS限制同时执行用户级任务的操作系统线
- GOMAXPROCS默认为系统核数
P队列
P有两种队列,本地队列和全局队列:
- 本地队列:当前P的队列,本地队列是Lock-Free,没有数据竞争问题,无需加锁处理,可以提升处理速度。
- 全局队列:全局队列为了保证多个P之间任务的平衡。所有M共享P全局队列,为保证数据竞争问题,需要加锁处理。相比本地队列处理速度要低于全局队列
1// 源码位置:src/runtime/runtime2.go
2type p struct {
3 // 在所有p列表中的索引
4 id int32
5 status uint32 // one of pidle/prunning/...
6 link puintptr
7 // 每调度一次加一
8 schedtick uint32 // incremented on every scheduler call
9 // 每次系统调用加一
10 syscalltick uint32 // incremented on every system call
11 // 用于 sysmon 线程记录被监控p的系统调用时间和运行时间
12 sysmontick sysmontick // last tick observed by sysmon
13 // 指向绑定的m,p是idle的话,该指针为空
14 m muintptr // back-link to associated m (nil if idle)
15 mcache *mcache
16 pcache pageCache
17 raceprocctx uintptr
18
19 deferpool [5][]*_defer // pool of available defer structs of different sizes (see panic.go)
20 deferpoolbuf [5][32]*_defer
21
22 // Cache of goroutine ids, amortizes accesses to runtime·sched.goidgen.
23 goidcache uint64
24 goidcacheend uint64
25
26 // Queue of runnable goroutines. Accessed without lock.
27 // 可运行的Groutine队列,队列头
28 runqhead uint32
29 // 可运行的Groutine队列,队列尾
30 runqtail uint32
31 // 保存q的数组,只能存放256个,超出的要放到全局队列
32 runq [256]guintptr
33 // runnext, if non-nil, is a runnable G that was ready'd by
34 // the current G and should be run next instead of what's in
35 // runq if there's time remaining in the running G's time
36 // slice. It will inherit the time left in the current time
37 // slice. If a set of goroutines is locked in a
38 // communicate-and-wait pattern, this schedules that set as a
39 // unit and eliminates the (potentially large) scheduling
40 // latency that otherwise arises from adding the ready'd
41 // goroutines to the end of the run queue.
42 // 下一个运行的g
43 runnext guintptr
44
45 // Available G's (status == Gdead)
46 // 空闲的g
47 gFree struct {
48 gList
49 n int32
50 }
51
52 sudogcache []*sudog
53 sudogbuf [128]*sudog
54
55 // Cache of mspan objects from the heap.
56 mspancache struct {
57 // We need an explicit length here because this field is used
58 // in allocation codepaths where write barriers are not allowed,
59 // and eliminating the write barrier/keeping it eliminated from
60 // slice updates is tricky, moreso than just managing the length
61 // ourselves.
62 len int
63 buf [128]*mspan
64 }
65
66 tracebuf traceBufPtr
67
68 // traceSweep indicates the sweep events should be traced.
69 // This is used to defer the sweep start event until a span
70 // has actually been swept.
71 traceSweep bool
72 // traceSwept and traceReclaimed track the number of bytes
73 // swept and reclaimed by sweeping in the current sweep loop.
74 traceSwept, traceReclaimed uintptr
75
76 palloc persistentAlloc // per-P to avoid mutex
77
78 _ uint32 // Alignment for atomic fields below
79
80 // The when field of the first entry on the timer heap.
81 // This is updated using atomic functions.
82 // This is 0 if the timer heap is empty.
83 timer0When uint64
84
85 // Per-P GC state
86 gcAssistTime int64 // Nanoseconds in assistAlloc
87 gcFractionalMarkTime int64 // Nanoseconds in fractional mark worker (atomic)
88 gcBgMarkWorker guintptr // (atomic)
89 gcMarkWorkerMode gcMarkWorkerMode
90
91 // gcMarkWorkerStartTime is the nanotime() at which this mark
92 // worker started.
93 gcMarkWorkerStartTime int64
94
95 // gcw is this P's GC work buffer cache. The work buffer is
96 // filled by write barriers, drained by mutator assists, and
97 // disposed on certain GC state transitions.
98 gcw gcWork
99
100 // wbBuf is this P's GC write barrier buffer.
101 //
102 // TODO: Consider caching this in the running G.
103 wbBuf wbBuf
104
105 runSafePointFn uint32 // if 1, run sched.safePointFn at next safe point
106
107 // Lock for timers. We normally access the timers while running
108 // on this P, but the scheduler can also do it from a different P.
109 timersLock mutex
110
111 // Actions to take at some time. This is used to implement the
112 // standard library's time package.
113 // Must hold timersLock to access.
114 timers []*timer
115
116 // Number of timers in P's heap.
117 // Modified using atomic instructions.
118 numTimers uint32
119
120 // Number of timerModifiedEarlier timers on P's heap.
121 // This should only be modified while holding timersLock,
122 // or while the timer status is in a transient state
123 // such as timerModifying.
124 adjustTimers uint32
125
126 // Number of timerDeleted timers in P's heap.
127 // Modified using atomic instructions.
128 deletedTimers uint32
129
130 // Race context used while executing timer functions.
131 timerRaceCtx uintptr
132
133 // preempt is set to indicate that this P should be enter the
134 // scheduler ASAP (regardless of what G is running on it).
135 preempt bool
136
137 pad cpu.CacheLinePad
138}
M 数据结构
- M代表一个线程,每次创建一个M时,都有一个底层线程创建
- 所有的G任务,都是在M上执行
- 两个特殊的G
- g0:带有调度栈的Groutine,是一个比较特殊的Groutine, g0的栈是对应的M对应的线程的真实内核栈
- curg: 结构体M当前绑定的结构体G
1// 源码位置:src/runtime/runtime2.go
2type m struct {
3 // 带有调度栈的Groutine,是一个比较特殊的Groutine
4 // g0的栈是对应的M对应的线程的真实内核栈
5 g0 *g // goroutine with scheduling stack
6 morebuf gobuf // gobuf arg to morestack
7 divmod uint32 // div/mod denominator for arm - known to liblink
8
9 // Fields not known to debuggers.
10 procid uint64 // for debuggers, but offset not hard-coded
11 gsignal *g // signal-handling g
12 goSigStack gsignalStack // Go-allocated signal handling stack
13 sigmask sigset // storage for saved signal mask
14 // 线程本地存储,实现m与工作线程的绑定
15 tls [6]uintptr // thread-local storage (for x86 extern register)
16 mstartfn func()
17 // 当前绑定的、正在运行的groutine
18 curg *g // current running goroutine
19 caughtsig guintptr // goroutine running during fatal signal
20 // 关联p,需要执行的代码
21 p puintptr // attached p for executing go code (nil if not executing go code)
22 nextp puintptr
23 oldp puintptr // the p that was attached before executing a syscall
24 id int64
25 mallocing int32
26 throwing int32
27 // 如果不为空字符串,保持curg始终在这个m上运行
28 preemptoff string // if != "", keep curg running on this m
29 locks int32
30 dying int32
31 profilehz int32
32 // 自旋标志,true表示正在从其他线程偷g
33 spinning bool // m is out of work and is actively looking for work
34 // m阻塞在note上
35 blocked bool // m is blocked on a note
36 newSigstack bool // minit on C thread called sigaltstack
37 printlock int8
38 // 正在执行cgo
39 incgo bool // m is executing a cgo call
40 freeWait uint32 // if == 0, safe to free g0 and delete m (atomic)
41 fastrand [2]uint32
42 needextram bool
43 traceback uint8
44 // cgo调用总次数
45 ncgocall uint64 // number of cgo calls in total
46 ncgo int32 // number of cgo calls currently in progress
47 cgoCallersUse uint32 // if non-zero, cgoCallers in use temporarily
48 cgoCallers *cgoCallers // cgo traceback if crashing in cgo call
49 // 没有groutine需要执行,工作线程睡眠在这个成员上
50 // 其它线程通过这个 park 唤醒该工作线程
51 park note
52 // 所有工作线程链表
53 alllink *m // on allm
54 schedlink muintptr
55 mcache *mcache
56 lockedg guintptr
57 createstack [32]uintptr // stack that created this thread.
58 lockedExt uint32 // tracking for external LockOSThread
59 lockedInt uint32 // tracking for internal lockOSThread
60 // 正在等待锁的下一个m
61 nextwaitm muintptr // next m waiting for lock
62 waitunlockf func(*g, unsafe.Pointer) bool
63 waitlock unsafe.Pointer
64 waittraceev byte
65 waittraceskip int
66 startingtrace bool
67 syscalltick uint32
68 freelink *m // on sched.freem
69
70 // these are here because they are too large to be on the stack
71 // of low-level NOSPLIT functions.
72 libcall libcall
73 libcallpc uintptr // for cpu profiler
74 libcallsp uintptr
75 libcallg guintptr
76 syscall libcall // stores syscall parameters on windows
77
78 // 寄存器信息,用于恢复现场
79 vdsoSP uintptr // SP for traceback while in VDSO call (0 if not in call)
80 vdsoPC uintptr // PC for traceback while in VDSO call
81
82 // preemptGen counts the number of completed preemption
83 // signals. This is used to detect when a preemption is
84 // requested, but fails. Accessed atomically.
85 preemptGen uint32
86
87 // Whether this is a pending preemption signal on this M.
88 // Accessed atomically.
89 signalPending uint32
90
91 dlogPerM
92
93 mOS
94}
go func()到底做了什么
源码中的 _StackMin 指明了栈的大小为2k
- 首选创建G对象,G对象保存到P本地队列(超出256)或者全局队列
- P此时去唤醒一个M。
- P继续执行
- M寻找是否有可以执行的P,如果有则将G挂到P上
- 接下来M执行调度循环
- 调用G
- 执行
- 清理现场
- 继续找新的G
- M执行过程中,会进行上下文切换,切换时将现场寄存器信息保存到G对象的成员里
- G下次被调度到执行时,从自身对象上恢复寄存器信息继续执行
1// 源码位置:sr/runtime/proc.go
2func newproc(siz int32, fn *funcval) {
3 argp := add(unsafe.Pointer(&fn), sys.PtrSize)
4 gp := getg()
5 pc := getcallerpc()
6 systemstack(func() {
7 // 内部调用了newproc1函数
8 newproc1(fn, argp, siz, gp, pc)
9 })
10}
11
12// _StackMin = 2048 默认栈大小为2k
13// newg = malg(_StackMin) 初始化栈大小
14func newproc1(fn *funcval, argp unsafe.Pointer, narg int32, callergp *g, callerpc uintptr) {
15 _g_ := getg()
16
17 if fn == nil {
18 _g_.m.throwing = -1 // do not dump full stacks
19 throw("go of nil func value")
20 }
21 acquirem() // disable preemption because it can be holding p in a local var
22 siz := narg
23 siz = (siz + 7) &^ 7
24
25 // We could allocate a larger initial stack if necessary.
26 // Not worth it: this is almost always an error.
27 // 4*sizeof(uintreg): extra space added below
28 // sizeof(uintreg): caller's LR (arm) or return address (x86, in gostartcall).
29 if siz >= _StackMin-4*sys.RegSize-sys.RegSize {
30 throw("newproc: function arguments too large for new goroutine")
31 }
32
33 _p_ := _g_.m.p.ptr()
34 newg := gfget(_p_)
35 // 初始化栈大小
36 if newg == nil {
37 newg = malg(_StackMin)
38 casgstatus(newg, _Gidle, _Gdead)
39 allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
40 }
41 if newg.stack.hi == 0 {
42 throw("newproc1: newg missing stack")
43 }
44
45 if readgstatus(newg) != _Gdead {
46 throw("newproc1: new g is not Gdead")
47 }
48
49 totalSize := 4*sys.RegSize + uintptr(siz) + sys.MinFrameSize // extra space in case of reads slightly beyond frame
50 totalSize += -totalSize & (sys.SpAlign - 1) // align to spAlign
51 sp := newg.stack.hi - totalSize
52 spArg := sp
53 if usesLR {
54 // caller's LR
55 *(*uintptr)(unsafe.Pointer(sp)) = 0
56 prepGoExitFrame(sp)
57 spArg += sys.MinFrameSize
58 }
59 if narg > 0 {
60 memmove(unsafe.Pointer(spArg), argp, uintptr(narg))
61 // This is a stack-to-stack copy. If write barriers
62 // are enabled and the source stack is grey (the
63 // destination is always black), then perform a
64 // barrier copy. We do this *after* the memmove
65 // because the destination stack may have garbage on
66 // it.
67 if writeBarrier.needed && !_g_.m.curg.gcscandone {
68 f := findfunc(fn.fn)
69 stkmap := (*stackmap)(funcdata(f, _FUNCDATA_ArgsPointerMaps))
70 if stkmap.nbit > 0 {
71 // We're in the prologue, so it's always stack map index 0.
72 bv := stackmapdata(stkmap, 0)
73 bulkBarrierBitmap(spArg, spArg, uintptr(bv.n)*sys.PtrSize, 0, bv.bytedata)
74 }
75 }
76 }
77
78 memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))
79 newg.sched.sp = sp
80 newg.stktopsp = sp
81 newg.sched.pc = funcPC(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function
82 newg.sched.g = guintptr(unsafe.Pointer(newg))
83 gostartcallfn(&newg.sched, fn)
84 newg.gopc = callerpc
85 newg.ancestors = saveAncestors(callergp)
86 newg.startpc = fn.fn
87 if _g_.m.curg != nil {
88 newg.labels = _g_.m.curg.labels
89 }
90 if isSystemGoroutine(newg, false) {
91 atomic.Xadd(&sched.ngsys, +1)
92 }
93 casgstatus(newg, _Gdead, _Grunnable)
94
95 if _p_.goidcache == _p_.goidcacheend {
96 // Sched.goidgen is the last allocated id,
97 // this batch must be [sched.goidgen+1, sched.goidgen+GoidCacheBatch].
98 // At startup sched.goidgen=0, so main goroutine receives goid=1.
99 _p_.goidcache = atomic.Xadd64(&sched.goidgen, _GoidCacheBatch)
100 _p_.goidcache -= _GoidCacheBatch - 1
101 _p_.goidcacheend = _p_.goidcache + _GoidCacheBatch
102 }
103 newg.goid = int64(_p_.goidcache)
104 _p_.goidcache++
105 if raceenabled {
106 newg.racectx = racegostart(callerpc)
107 }
108 if trace.enabled {
109 traceGoCreate(newg, newg.startpc)
110 }
111 runqput(_p_, newg, true)
112
113 if atomic.Load(&sched.npidle) != 0 && atomic.Load(&sched.nmspinning) == 0 && mainStarted {
114 wakep()
115 }
116 releasem(_g_.m)
117}
全局调度器
- 通过lock来全局管控一些全局操作
1type schedt struct {
2 // accessed atomically. keep at top to ensure alignment on 32-bit systems.
3 // 需要原子访问
4 goidgen uint64
5 lastpoll uint64 // time of last network poll, 0 if currently polling
6 pollUntil uint64 // time to which current poll is sleeping
7
8 lock mutex
9
10 // When increasing nmidle, nmidlelocked, nmsys, or nmfreed, be
11 // sure to call checkdead().
12 // 空闲的工作线程组成的列表
13 midle muintptr // idle m's waiting for work
14 // 空闲的工作线程数量
15 nmidle int32 // number of idle m's waiting for work
16 // 空闲的、且被lock的m计数
17 nmidlelocked int32 // number of locked m's waiting for work
18 // 创建的工作线程的数量
19 mnext int64 // number of m's that have been created and next M ID
20 // 最多能创建的工作线程数量
21 maxmcount int32 // maximum number of m's allowed (or die)
22 nmsys int32 // number of system m's not counted for deadlock
23 nmfreed int64 // cumulative number of freed m's
24
25 // 系统中所有Groutine的数量,自动更新
26 ngsys uint32 // number of system goroutines; updated atomically
27 // 空闲的p结构体对象组成的链表
28 pidle puintptr // idle p's
29 // 空闲的p结构体对象数量
30 npidle uint32
31 nmspinning uint32 // See "Worker thread parking/unparking" comment in proc.go.
32
33 // Global runnable queue.
34 // 全局可运行的G队列
35 runq gQueue
36 runqsize int32
37
38 // disable controls selective disabling of the scheduler.
39 //
40 // Use schedEnableUser to control this.
41 //
42 // disable is protected by sched.lock.
43 disable struct {
44 // user disables scheduling of user goroutines.
45 user bool
46 runnable gQueue // pending runnable Gs
47 n int32 // length of runnable
48 }
49
50 // Global cache of dead G's.
51 // 全局的已退出goroutine,缓存下来,避免每次都要重新分配内存
52 gFree struct {
53 lock mutex
54 stack gList // Gs with stacks
55 noStack gList // Gs without stacks
56 n int32
57 }
58
59 // Central cache of sudog structs.
60 sudoglock mutex
61 sudogcache *sudog
62
63 // Central pool of available defer structs of different sizes.
64 deferlock mutex
65 deferpool [5]*_defer
66
67 // freem is the list of m's waiting to be freed when their
68 // m.exited is set. Linked through m.freelink.
69 freem *m
70
71 gcwaiting uint32 // gc is waiting to run
72 stopwait int32
73 stopnote note
74 sysmonwait uint32
75 sysmonnote note
76
77 // safepointFn should be called on each P at the next GC
78 // safepoint if p.runSafePointFn is set.
79 safePointFn func(*p)
80 safePointWait int32
81 safePointNote note
82
83 profilehz int32 // cpu profiling rate
84
85 procresizetime int64 // nanotime() of last change to gomaxprocs
86 totaltime int64 // ∫gomaxprocs dt up to procresizetime
87}
88
89type gQueue struct {
90 head guintptr
91 tail guintptr
92}
93
94// 全局变量
95// src/runtime/proc.go
96var (
97 // 进程的主线程
98 m0 m
99 // m0的g0
100 g0 g
101 raceprocctx0 uintptr
102)
103
104// 全局变量
105// src/runtime/runtime2.go
106var (
107 // 所有g的长度
108 allglen uintptr
109 // 保存所有的m
110 allm *m
111 // 保存所有的p
112 allp []*p // len(allp) == gomaxprocs; may change at safe points, otherwise immutable
113 allpLock mutex // Protects P-less reads of allp and all writes
114 // p的最大值,默认等于ncpu
115 gomaxprocs int32
116 // 程序启动时,osinit函数获取该值
117 ncpu int32
118 forcegc forcegcstate
119 // 全局调度器
120 sched schedt
121 newprocs int32
122
123 // Information about what cpu features are available.
124 // Packages outside the runtime should not use these
125 // as they are not an external api.
126 // Set on startup in asm_{386,amd64}.s
127 processorVersionInfo uint32
128 isIntel bool
129 lfenceBeforeRdtsc bool
130
131 goarm uint8 // set by cmd/link on arm systems
132 framepointer_enabled bool // set by cmd/link
133)